

Introduction
Within the new world of Industry 4.0, companies are collecting and storing more data than ever before. This due to industrial sensors becoming more cost-effective and smarter, allowing for more instruments to be network connected. IoT initiatives have also enabled connectivity never possible before. Vast amounts of data points and information can thus be gathered from across the entire production process. Most companies know that there is a lot of value in this data, but knowing how to identify, extract, sort and understand the value can be like looking for the needle in a haystack.
Artificial Intelligence (AI) and specifically Machine Learning (ML), is a great tool that can be utilised to make sense and extract value from this information. The Oxford dictionary defines ML as: ‘The use and development of computer systems that are able to learn and adapt without following explicit instructions, by using algorithms and statistical models to analyse and draw inferences from patterns in data.’
This might sound very futuristic, mathematical and way too theoretical (not to mention expensive) to be used in practical industrial applications. However, the concept of ML was defined as far back as 1959 and as processing power has progressed and matured over the years, so have AI and ML. Technology providers have started to incorporate AI and ML into their product suites, enabling it to move away from pure theoretical mathematical concepts to configurable practical products. Today, both small and large organisations are able to utilise ML tools off-the-shelf for a wide variety of industrial applications such as:
• Early anomaly detection to prevent costly failures and downtime.
• Process optimisation.
• Predictive analytics and forecasting.
• Safer operations.
• Continuous quality monitoring and improvement.
• Enabling more efficient production processes.
What makes ‘Industrial’ Machine Learning (IML) different?
IML platforms provide software-based modelling for equipment or processes using advanced pattern recognition (APR). It makes use of historic and realtime data to predict what is going to happen next. The system continuously monitors behaviour in realtime and compares current conditions to historical patterns to identify anomalies and drift.
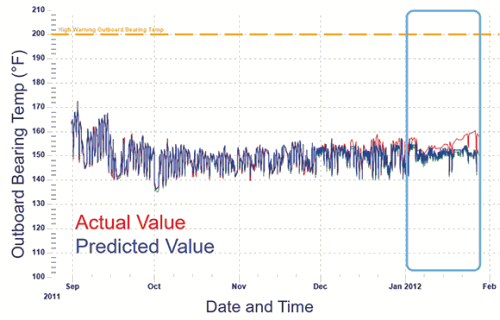
Should an anomaly be detected, the system will raise an alarm, notification or alert to the appropriate users. It also offers advanced analysis capabilities for problem identification and root cause analysis. Figure 1 shows where a ‘current’ value started deviating from the ‘predicted value, identifying an anomaly well in advance of the equipment failure.
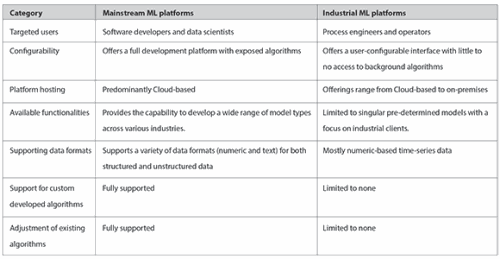
Most mainstream platforms that offer ML (i.e. Microsoft Azure, Amazon Web Services, IBM etc.) provide flexible and configurable capabilities for a wide range of sectors. Although these tools are extremely powerful, they are typically utilised by data scientists who understand how to categorise the various data streams, can perform the pre-processing or ‘cleaning’ of data and know how to select the right mathematical algorithms and parameters for effective modelling. Although these tools are powerful, most companies do not employ data scientists and definitely not on the plant floor.

In comparison, IML platforms available today are purpose-built tools designed to be used by process engineers and managers who have the relevant plant and domain knowledge, but not the grounding in data science.
The table above highlights some of the key differences between these two types of platforms.
As the table shows, IML platforms trade flexibility for user configurability, which addresses a specific need for industrial clients who require only a certain subset of ML functionality, for which pre-determined algorithms and parameters can be packaged. The focus is thus on making these platforms easily configurable for non-data science users by automating the underlying complexities. This ensures that the product operates in a specifically defined manner, which in turn improves stability and reliability.
There is thus no need for data scientists or any mathematical understanding, as everything is configured or automated. IML works predominantly with industrial time-series data, but can also accommodate event-based data. It automatically classifies incoming data according to historic values, such as whether the signal is Boolean, Smooth, Noisy, a Step or Categorical and checks whether the signal has enough historical data points to be meaningful.
At high level, IML offers the creation of two types of ML models, namely: anomaly detection and forecasting.
Anomaly detection: understand what is happening now
For anomaly detection, the ML model ‘learns’ the normal behaviour of a specific process or equipment by ingesting and analysing large amounts of historical data. The ‘model’ is configured by the user and made up of a number of variables that indicate equipment or process ‘health’. Based on the historical information, the model learns how a specific variable is expected to behave, based on its relative relation to the rest of the variables configured within the model.
The model will then continuously and in realtime, monitor and evaluate the ‘actual’ value of the variable, as obtained from the plant, against the ‘expected’ value based on the historically defined ‘normal’ or ‘healthy’ behaviour. Should the difference between these two values exceed a configured threshold, then the system will flag it as an anomaly.
Anomaly detection is typically used for predictive maintenance as it can identify equipment issues as they start to occur, well in advance of actual equipment breakdown. It can also be used to monitor production efficiencies as it highlights any processes or parameters that are deviating from expected behaviour.
Forecasting: understand what is about to happen
Forecasting is used to predict the future value (within an accuracy range) of a specific variable within a user-specified timescale. It shows, in effect, what a variable value will be a few minutes or hours from the present.
Forecasting uses historical data to learn how a process normally behaves. It uses multiple variables and can learn many different modes of operation and correlation at once. It will predict multiple future data points from ‘now’ to the user-selected future target (1, 2, 4 hours etc.). As with anomaly detection, in order to achieve an accurate model prediction, the inputs must have predictive power (relevance) to the target output variable and time.
Forecasting is typically used to increase process efficiency. Knowing that a batch, or a process, is going to be out of specification within the next hour (based on current data) gives one the ability to pre-emptively adjust process set points now (either manually or automatically) to prevent the possible ‘out-of-specification’ event.
Part 2 of this article will be published in the May issue of SA Instrumentation and Control and will cover the practical implementation of Industrial Machine learning. Interested readers who wish to skip ahead can find the full article at https://www.instrumentation.co.za/12850r
| Tel: | +27 12 349 2919 |
| Email: | [email protected] |
| www: | www.iritron.co.za |
| Articles: | More information and articles about Iritron |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version